
Most enterprise AI projects eventually hit a predictable wall. It's rarely a model problem or a compute problem; it's almost always a data problem. We see poor quality, fragmented pipelines, and ungoverned access stalling great ideas. The AI was fine, but the fuel wasn't. Databricks was built to solve this exact bottleneck.
The Gap Between Notebooks and Production
The statistics tell a sobering story. McKinsey reports that only a tiny fraction of executives feel their AI rollouts are truly mature. While global spending on generative AI is skyrocketing, much of that investment is being swallowed by a familiar trap: systems that work brilliantly in a controlled demo but fall apart when they meet messy, real-world enterprise data.
The culprit is rarely the model itself. GPT-4 or Gemini are incredibly capable. The real issue is the data they're fed: siloed lakes, stale documents, and pipelines that don't understand lineage or quality. Without solid data engineering, AI is often just a very expensive way to get things wrong.
This is where the Databricks approach changes things. It isn't just an AI company; it's a data company that built a stack specifically to turn raw information into AI-ready fuel. The idea is straightforward: the same platform running your ETL pipelines should also train your models and serve your agents. One lakehouse, one governance model, and one clear path from source to answer.
The Unified Stack: Where Pipelines Meet Production
We've found that the most successful teams treat data pipelines and AI pipelines as one and the same. They share storage, governance, and orchestration. When you separate them, you create the fragmentation that causes production AI to drift or fail.
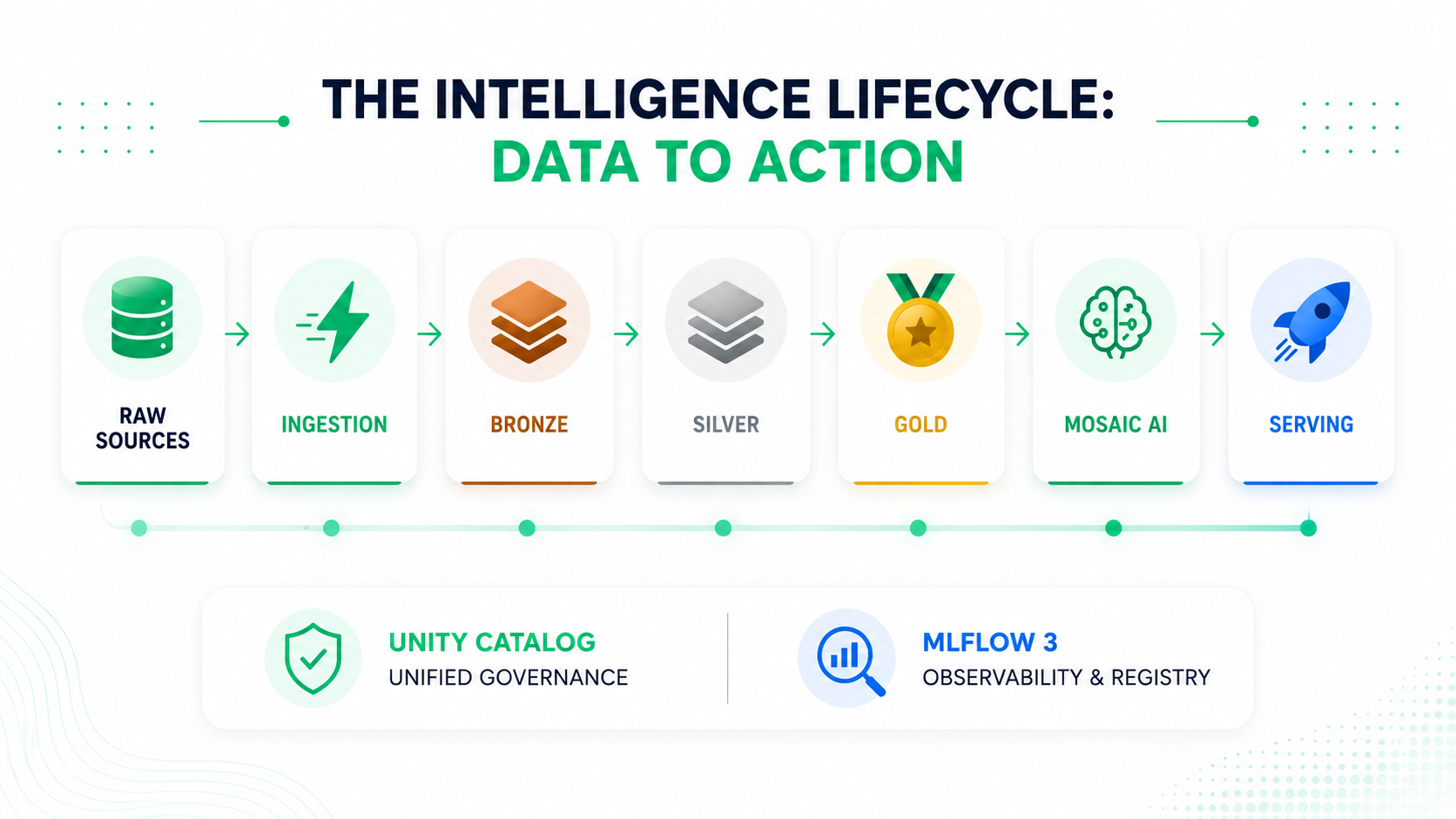
The Medallion architecture isn't just a best practice for dashboards anymore; it's the supply chain for AI. Every agent powered by Databricks pulls its context from this governed pipeline. If quality drops upstream, alerts fire before your model starts hallucinating for customers.
Retrieval is a Data Engineering Problem
Retrieval-Augmented Generation (RAG) is now the standard for enterprise AI. Instead of hoping a model remembers your company's facts, RAG lets it look up live data. The quality of that answer depends entirely on the quality of the search, which makes RAG a data engineering challenge at its core.
On Databricks, this is native. Documents arrive in Unity Catalog, and Lakeflow handles the messy work of chunking and metadata. Mosaic AI Vector Search stays in sync with your Delta tables automatically. This means that when a document changes, your AI's "brain" updates without you having to build a custom sync script.
"By keeping embeddings synchronized with Delta tables, your AI always queries fresh data. You stop managing a separate vector database and start managing a data lifecycle."
# RAG as a simple, governed chain
from databricks.vector_search.client import VectorSearchClient
client = VectorSearchClient()
# Search with built-in security: users only see what they have access to
results = client.get_index(
endpoint_name="prod-endpoint",
index_name="catalog.schema.docs"
).similarity_search(
query_text=user_query,
columns=["text", "source"],
num_results=5
)Mosaic AI & MLflow 3: Built for Agents
Mosaic AI has evolved into a deeply integrated system for the entire AI lifecycle. From our partner perspective, the announcements at the recent summit have fundamentally changed how we build for clients.
Managed Training
Fine-tune open-source models on your data without wrestling with GPU infrastructure. It's now a managed service.
Agent Bricks
A tool to quickly generate domain-specific benchmarks and synthetic data to make your agents more accurate.
MLflow 3
Redesigned for the GenAI era with better tracing and a registry specifically for versioning your prompts.
Unity AI Gateway
One entry point to manage all your model APIs, with built-in cost controls and safety guardrails.
The common thread here is Unity Catalog. Every model, prompt, and log is a governed asset. This level of coherence is what's usually missing when teams try to stitch together five different AI tools.
Garbage In, Hallucination Out
AI has given data quality a new sense of urgency. What we used to call "bad data" is now a safety risk. A pipeline that lets malformed records through isn't just breaking a report; it's corrupting the context of an agent talking to a customer.
| Metric | The Old View | The AI View |
|---|---|---|
| Quality | Dashboard alerts | ✓ Safety guardrails for agents |
| Freshness | Hours or days | ✓ Real-time context window |
| Lineage | Compliance logs | ✓ Explaining why the model said that |
| Access | SQL permissions | ✓ Context-aware security |
Lakehouse Monitoring now extends this visibility all the way to the model output. When a data engineer sees a spike in null values, the AI team sees the corresponding drop in model confidence. They aren't two separate problems anymore; they are two sides of the same coin.
The Intelligence Was Always in Your Data
There's a popular story where models are magic and data is just an input. That story has had a rough year. The teams struggling right now are the ones that tried to bolt LLMs onto messy, unmanaged data estates.
The teams winning are those that treated data engineering as the foundation. They put governance first, implemented quality contracts, and realized their data engineers are the most important members of the AI team. At its heart, the future of AI is the future of data engineering.
As a Databricks partner, we're focused on helping you build that foundation deliberately. The intelligence is already there in your data; we're just here to help you unlock it.
Ready to build for real? We help teams move past the "cool demo" phase and build AI systems that actually work in production. Contact our team to explore how a robust Databricks data foundation can accelerate your enterprise AI goals.



